The Rise, Fall, and Future of Vector Databases: How to Pick the One That Lasts
Special thanks to Doug Turnbull, Daniel Svonava, Atita Arora, Aarne Talman, Saurabh Rai, Andre Zayarni, Leo Boytsov, Pat Lasserre and Bob van Luijt for reading and commenting the drafts of this post
Update: I recorded a Vector Podcast episode, with the help of AI (NotebookLM), you might want to check out:
Jo Kristian Bergum recently wrote a massively influential X post: “The rise and fall of the vector database infrastructure category”.
I jokingly replied in a comment:
It is all good to chart what happened or happens on the industry level, but what a regular user should do? How to choose a vector database in this vastly fragmented space? This runs on the assumption, that for your product or project idea you’ve decided and are certain, that you need to use vector embeddings to represent semantic (or other) relations between objects (products, texts, images, videos, emails and so on).
But first, let’s quickly go through the Rise and The Fall of vector databases — before talking about the Future.
The Rise

As you know, in my own way I participated in creating the emerging trend on vector databases by interviewing and cataloging the players present on the market 3 years ago. Behind the scenes I even advised a VC firm to pick a vector database between (back then) two main contenders. I have talked about Vector Search and Vector Databases in many forums, including Berlin Buzzwords (in 2021 and 2022), Haystack, London IR Meetup, Open NLP Meetup. I have also launched the Vector Podcast in 2021 as a way to explore this new trend. Of course since then the podcast has expanded to more topics, like LLMs, search, data science, neural search frameworks. And, most recently, I have discussed vector search and vector databases in our recent course on LLMs and Generative AI.
I also attempted to give my advice for how to go about choosing a vector database 2 years ago:
I personally did not feel like it was a gold rush, because a database to me is just a tool: it either covers the facets of your use case, is customizable, scalable and performant, or not. I do realize that companies behind these technologies have raised money to attract talent and build a better version of themselves over time. But it is still a tool, and I sometimes found in my client practice and own projects some of the vector databases simply not fulfiling the basic needs of the application at hand.
In some e-commerce scenarios, I encountered challenges with vector databases that lacked support for critical features like faceted search. This underscored the importance of aligning the database’s capabilities with the application’s requirements, particularly for industries relying on advanced filtering and categorization.
The Fall

By the end of 2023, I noticed a shift in interest surrounding vector search. The readership for my earlier posts on vector databases began to decline, signaling that the topic might be losing its standalone appeal. This trend suggests that while vector search remains foundational, the conversation has expanded to encompass broader innovations like LLMs, multimodal search, and integrated AI workflows.
Here is how the readership looked like at the beginning (you can safely ignore the spike, because it was created by Greg Kogan’s successful repost on the Hacker News):
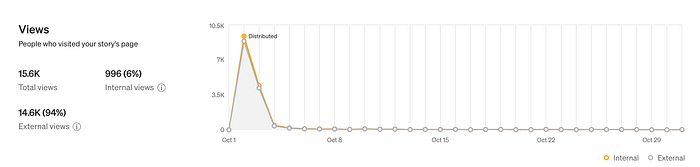
and then.. nothing. Well, not quite, but still: throughout 2021, 2022 the blog post received around 1–1,5K views per month. From January 2023 it jumped from 2K to 15K monthly views at its peak in April 2023.
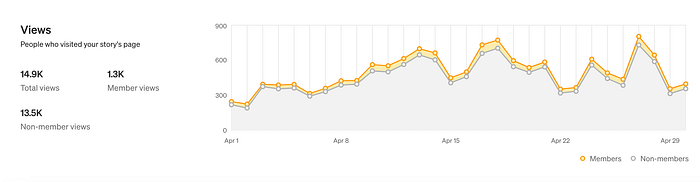
What personally was eye-opening for me, was that after Google, lots of users would email the blog post to each other. This speaks to the power of the mailing lists:
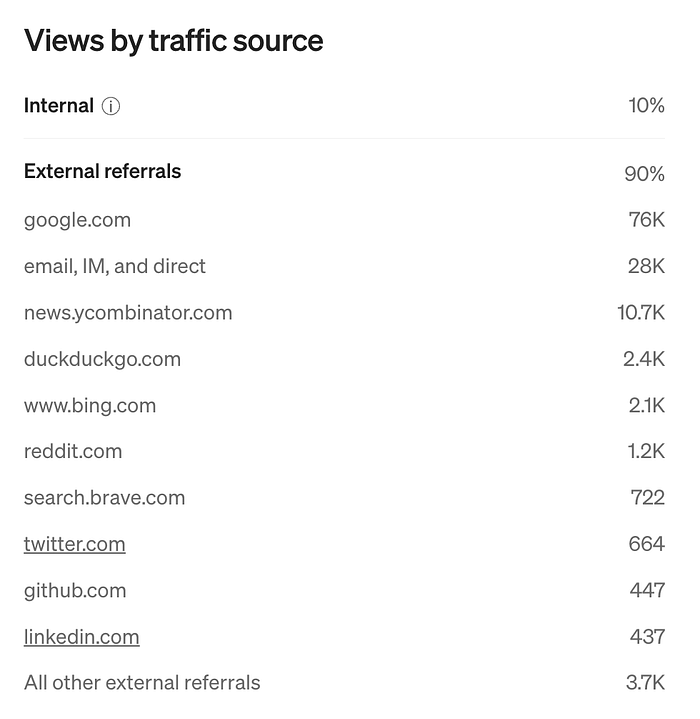
I asked ChatGPT about what happened in April 2023, and got reminded of the 3 investment deals:
In April 2023, several vector database startups secured substantial funding, reflecting growing interest and investment in this technology.
- Pinecone: Raised $100 million in a Series B round, elevating its valuation to $750 million. This investment aimed to enhance their vector database capabilities, crucial for AI applications. TechCrunch
- Weaviate: Secured $50 million in Series B funding to expand its AI-native vector database technology, addressing the increasing demand in AI application development. PR Newswire
- Qdrant: Obtained $7.5 million in seed funding, focusing on open-source vector similarity search solutions to support AI applications. Qdrant. In January of 2024 they raised $28 million. TechCrunch
Then I checked and found, that also Chroma raised $18 million in the same month of April 2023. PR
That was a super fruitful month for raising money in the vector database field! And perhaps, explains the resurfacing of my blog-post, as it has been viewed so far 121K+ times with 46K+ actual reads.
Let’s take a look at the Google Trends (worldwide, past 5 years):

We can see two spikes: in April 2023 and January / February 2024. Both of which are explainable by the mentioned investment deals and a subsequent coverage in media.
By December 2023, the views went back to 1K / month, however. In 2024 it fell to the really low numbers (hundred views / month). But given the age of the blog post, I don’t have high hopes anyway as it also misses lots of newer players, their way to position on the market and new functionality.
It is also interesting to see the change in product positioning. If in the beginning, all products were “vector databases”, today it is not this uniform. For example, Weaviate presents itself as an “AI-native database”, while Pinecone became a “knowledge platform”. Milvus seems to stick to the original “High-Peformance Vector Database”, same as Qdrant: “High-Performance Vector Search”. I did not check all other players, but you can find a pretty exhaustive list with comparison columns here.
As you can see, the market has partially (not all players) shifted away from the notion of a “vector database”, because frankly who cares? Many incumbent sql and nosql databases have implemented vector search since. So as Jo says in his blog post, database paradigms have merged and in many ways vector data type has become a marginal addition and a convenience. I’m doubtful, that this means the fall of the vector DB infrastructure category (because databases and companies still exist and are thriving), but if you feel differently, let me know in the comments.
Here I’d like to make a plug and say, that it is not the vectors that give you a better search or a smarter app. It is knowing the nitty-gritty of how to preprocess, model your data and how to chunk the textual modality (if you build RAG), which embedding model to pick, which LLM to use for generation, what to do with saturation in the presence of too many embeddings, how to minimize hallucinations and inaccuracy, how to add guardrails to your app logic (to for example not let it add a label of 2025 to something that happened in 2024), how to scale, how to reach cost-efficiency. And, perhaps, when to make a call and replace the embeddings in favor of keyword search with synonyms (and keep embeddings only for a cheaper reranking step).
Vector Database Guide

Okay, but that leaves a user in a pretty difficult spot. They see so many players on the vector search market and scratch their heads: what do we choose and why? All players seem to offer a pretty comparable functionality.
Here I give an updated guide, based on my own experience with vector search in research and production settings.
If I had to choose a db / vector search implementation for a project, I’d do this:
- Try FAISS. This is not a database, more of a search library, which can also create index on disk and scales to 1B+ vectors. We have used it with Aarne Talman in a project with 10M books and it was a breeze to work with it. The only limitation of FAISS is: it does not support filters (for example find K nearest vectors, but with a filter country=USA, or something similar). This can be a show-stopper. Of course, you can resort to post-filtering approach, but that can become very costly in terms of latency, because in the first go you may get all the items that fall outside your filter requirements.
- If you need to support fine-grained, controlled keyword search alongside vector search, consider using vector databases built on top of Lucene. These databases, such as OpenSearch, Elasticsearch, and Apache Solr, provide robust multilingual keyword search capabilities and leverage Lucene’s 25 years of battle-tested performance, scalability, and customizability. This combination ensures precision and flexibility for hybrid search use cases.
If you are working on a classic e-commerce use case that requires features like facets, sorting, grouping, and other functionalities essential for e-commerce users, it makes even more sense to leverage Lucene-based vector databases. For example, searching for “camera” in such systems can provide not only relevant results but also facet counts like “105 Kodak,” “53 Nikon,” and “32 Panasonic” — enriching the user experience.
That said, there are exceptions. For instance, Qdrant does support facets, as I recently learned from Andre Zayarni. This is an important consideration when evaluating the right database for your needs. - If you need something fancy, like late interaction model support, then choose the vector db, that supports it natively, like Qdrant or Vespa.
- Another big question to ask: how low-latency does your product have to be. If there are very tight constraints on this and high expected QPS (query per second), then go with a very low-latency db, like GSI APU (has a plugin for Elasticsearch / OpenSearch, paid) or with Vespa, or Hyperspace (uses FPGA to precompile your search logic and reduce latency or cost). I have heard from one CTO, that none of the openly available vector DBs scales to their workloads. So choose wisely, my friends™️.
- Finally: are you ready to allocate engineer time for setting up an open source DB (it can take years to master it) or is it easier to spend the money on using a cloud DB (for example CosmosDB in Azure or Vertex AI in GCP) or some API-like DB (Pinecone, Weaviate Cloud, Qdrant Cloud, Zilliz Cloud, Vespa Cloud etc)? This is what is commonly called an “opportunity cost”. You take away the focus in your team from building and shipping features towards setting up and maintaining the database. This can be a strategic choice to do so as well, though.
Community items

I invite you, the reader, to share your own way for choosing a vector database / library. Please reach out in the comments here or wherever you are reading this and I promise to review and add your item to the list below.
Your item / approach for choosing a vector database can be here:
- [Matt Collins] Beside complete vector databases or vector search frameworks, community also prefers to use extensions. One example is pgvector, which extends Postgres with vector search functionality.
Closing remarks: the future
I’ve been quietly waiting for the rise of Neural Search Frameworks (read the blog post for more details and my Vector Search Pyramid proposal). In my book, they would propell everything forward: vector databases, RAG, hybrid search, evaluation methods, model fine-tuning — all then comes together with a concerted meaning and aim to solve specific customer challenge. In other words, users will not need to be confronted with a difficult geeky choice of building blocks (like a database) and instead will reason about what is it that they aim to build. Thinking in the abstractions of the task and not of the components of the solution is what gives you vision for achieving greater heights. And of course, a good framework should give you methods for swapping any component / algorithm combination to maximize the yield on the metrics you care about. Has anyone built this yet? Or, perhaps, are building? Let me know in the comments!
It may well be that the answer is this new interesting direction called Compound AI Systems (thanks Pat Lasserre for sharing this with me). Citing from the blog post:

Hope you enjoyed reading this blog post, let me know what you think in the comments.
